Abstract
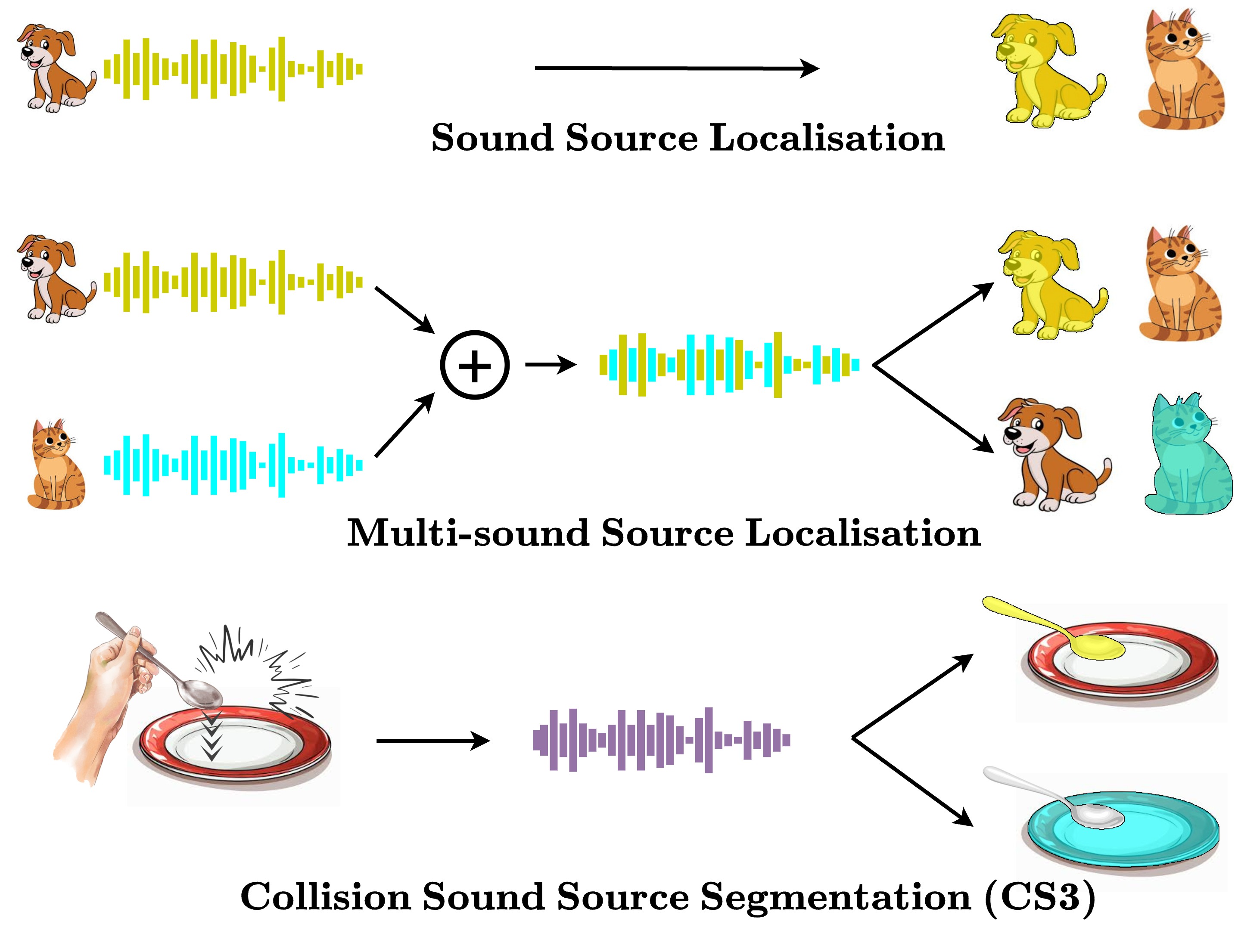
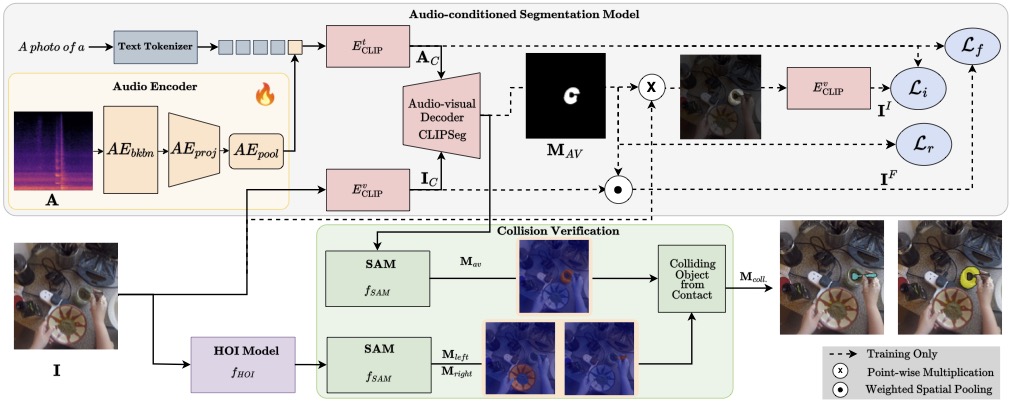
Humans excel at multisensory perception and can often recognise object properties from the sound of their interactions. Inspired by this, we propose the novel task of Collision Sound Source Segmentation (CS3), where we aim to segment the objects responsible for a collision sound in visual input (i.e. video frames from the collision clip), conditioned on the audio. This task presents unique challenges. Unlike isolated sound events, a collision sound arises from interactions between two objects, and the acoustic signature of the collision depends on both. We focus on egocentric video, where sounds are often clear, but the visual scene is cluttered, objects are small, and interactions are brief. To address these challenges, we propose a weakly-supervised method for audio-conditioned segmentation, utilising foundation models (CLIP and SAM2). We also incorporate egocentric cues, i.e. objects in hands, to find acting objects that can potentially be collision sound sources. Our approach outperforms competitive baselines by $3 \times$ and $4.7 \times$ in mIoU on two benchmarks we introduce for the CS3 task: EPIC-CS3 and Ego4D-CS3.