Kranti Kumar Parida 1, 2,
Siddharth Srivastava2,
Gaurav Sharma1, 2
1IIT Kanpur, 2TensorTour Inc.
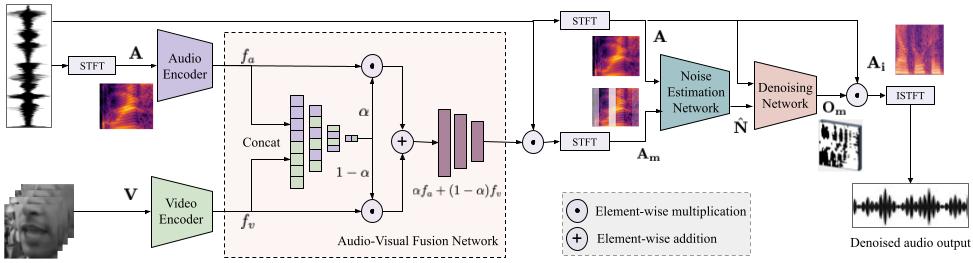
We address the problem of speech denoising where the goal is to extract clean speech signal from a noisy signal. Traditionally, the task of denoising has been performed using audio modality only. However, human speech perception is inherently multimodal where cues from visual modality are used to better understand what is being said in a noisy environment. Similar observation has been made with computational denoising methods, i.e., performance of audio only model improves when visual modality is added. Inspired by these findings we propose a novel audio-visual fusion network for adaptively combining both modalities for the task of speech audio denoising. We improve upon an existing audio only approach which first extracts the silent intervals (short pauses) and then uses them for estimating noise profile, which it eventually employs for denoising. We show that instead of explicitly extracting the silent region and then denoising, training an end-to-end network is more appropriate, and adding visual information, from lip regions, further improves the performance. We evaluate the proposed approach on a large scale audio-visual dataset Voxceleb2 and obtain state-of-the-art results. We also demonstrate generalization to unseen speakers at test time.
| Noisy Audio | Output | Remarks |
|---|---|---|
| Video recorded in a heavy background noise and can be found commonly for YouTubers recording cooking video.
Our method is able to extract out the clean signal. Note: This video was recorded by one of our group members and we have hidden the face to maintain privacy. Please note we have used the mouth region as required by our model and the face is hidden only for illustration. |
||
| A reporter reporting under a very windy condition. Our method is able to extract out the input speech signal.
Although our method degrades in the region where it overlaps with the strong wind noise but the speech is clean and the
words can be easily understood.
link: https://www.youtube.com/watch?v=zbdf1ayyijc |
||
| In this video a YouTuber is recording in a busy street where the audio is mixed with vehicle noise and other persons' voice.
Here, we can observe that the background noise like car honking and random chatter is decreased significantly. Also towards the end
of the video an engine like noise can be heard in the original video and this has completely been removed by our method.
link: https://www.youtube.com/watch?v=9qM2ZAJsKCg |
||
| Here, a reporter is reporting from a violent protest site and the input audio conatins a variety of backgorund noise.
Towards the end of the video, it can be seen that some explosive is thrown towards the reporter that makes a blast sound.
This blast sound is almost completely removed in our denoised output.
link: https://youtu.be/RH8S8RhtvHA?t=83 |
| SNR | Clean audio | Mixed audio | Audio-only | Video-only | Ours |
|---|---|---|---|---|---|
| -10 | |||||
| -10 | |||||
| -10 | |||||
| -7 | |||||
| -7 | |||||
| -7 | |||||
| -3 | |||||
| -3 | |||||
| -3 | |||||
| 0 | |||||
| 0 | |||||
| 0 | |||||
| 3 | |||||
| 3 | |||||
| 3 | |||||
| 7 | |||||
| 7 | |||||
| 7 | |||||
| 10 | |||||
| 10 | |||||
| 10 |
If you use the code or dataset from the project, please cite:
@article{parida2026noise,
title = {Noise Aware Audio-Visual Speech Denoising},
author = {Parida, Kranti Kumar and Srivastava, Siddharth and Sharma, Gaurav},
journal = {IEEE Transactions on Multimedia},
year = {2026}
}